一、单项选择题(1*9)
1.大数据发展历程:出现阶段、热门阶段和应用阶段 P2
2.大数据影响 P3
1)大数据对科学活动的影响
2)大数据对思维方式的影响
3)大数据对社会发展的影响
4)大数据对就业市场的影响
3. 人类在科学研究上先后经历了实验、理论、计算、数据思维四种范式 P3
4.大数据特征:数据量大、数据类型繁多、数据产生速度快及数据价值密度低 P5
5.ETL:提取、转换、加载 P7
6.大数据处理框架可分为三类:批处理系统、流处理系统和混合处理系统 P12
7.Requests状态码:200 成功,404 失败
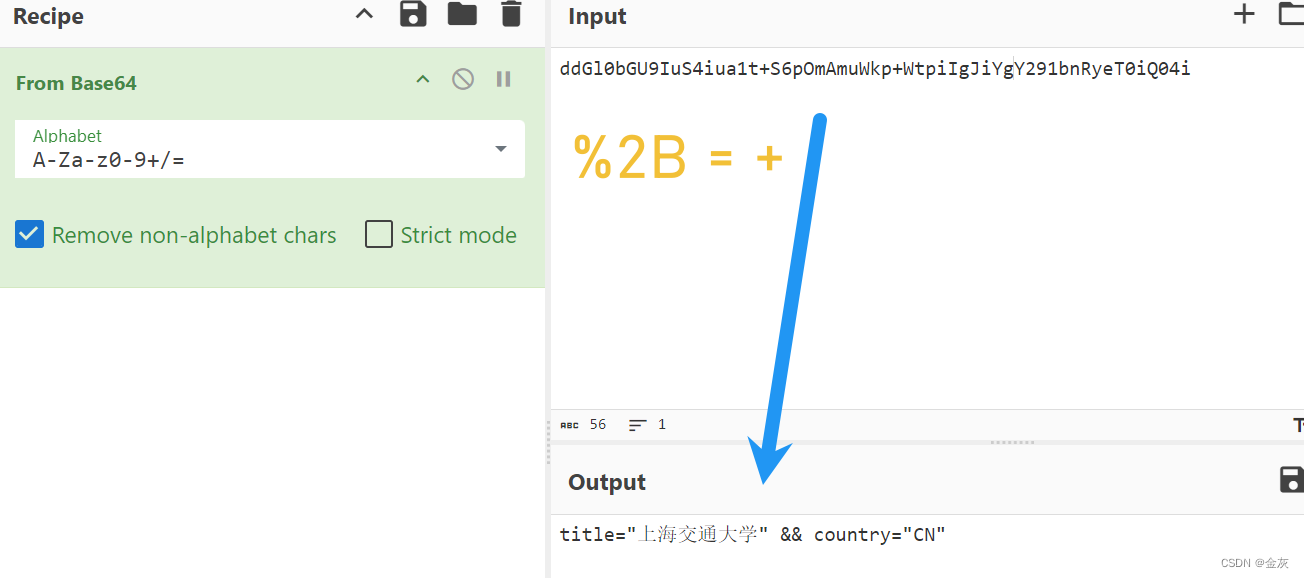
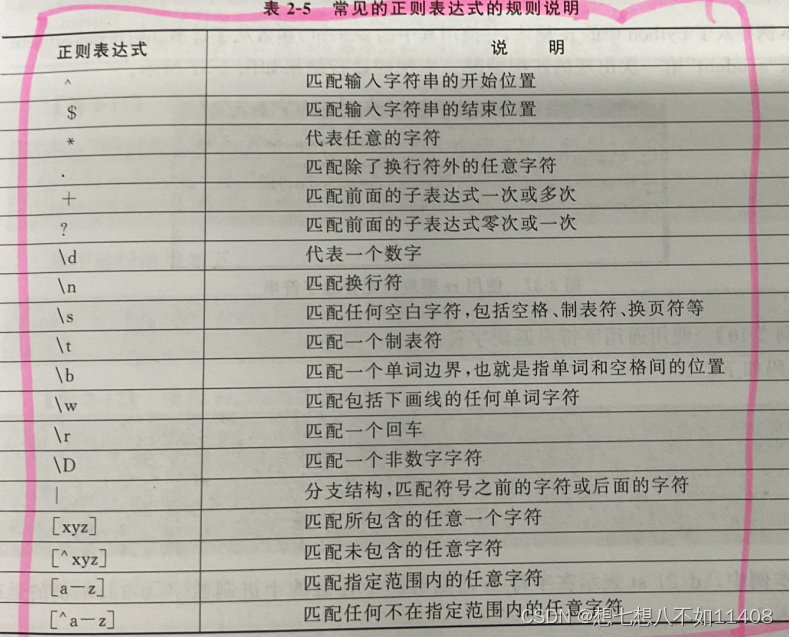
8.正则表达式:
9.Scrapy命令:P88

10.pandas一维数组、二维数组、方法的使用
在pandas库中有两个最基本的数据类型,即Series和DataFrame。其中Series代表一维数组,DataFrame代表二维数组。P277
sum() 对每一列求和
sum(1) 对每一行求和
df- * / () 做减法、乘法、除法
append() 对行或列扩充
reindex() 重新简历一个新的索引对象
drop() 丢弃不需要的数据值
sort_index() 对数据值 排序
idxmin 统计最小值索引
idxmax 统计最大值索引
cumsum 对数据值进行累加
11.python的使用
二、填空题(1*12)
1.命令:pip install beautifulsoup4
2.大数据类型:结构化数据、非结构化数据和半结构化数据
3.大数据存储是将数量巨大且难以收集、处理、分析的数据集合持久化到计算机中
4.大数据框架是可以进行大数据分析处理工具的集合,主要用于负责对大数据系统中的数据进行计算。
5.大数据获取方式包括爬虫爬取、用户留存、用户上传、数据交易和数据共享,

6.UA:UserAgent
7.Scrapy是使用Python语言编写的开源网络爬虫框架,也是一个为了爬取网站数据,提取结构性数据而编写的应用框架,简单易用并且是跨平台的。
8.目前实现数据抽取的方式:关系库中的数据抽取和非关系库中的数据抽取
数据抽取的关键技术:时间戳、触发器方式、全量删除插入
9.大数据分析与挖掘的主要内容:可视化分析和数据挖掘算法的选择
三、判断并改错(3*5)
1.Request对象用于描述一个HTTP请求,由Spider产生
2.Response对象用于描述一个HTTP响应
3.云数据库并非是一种全新的数据库技术,而只是以服务的方式提供数据库功能。
4.元组数据的元素不能改变,只能读取
5.Spider在项目中名称必须独一无二
6.Python的整型类似于Java的BigInteger类型,它的长度不受限制
7.Python区分整型和浮点型的唯一方式就是看有没有小数点
8.Python中布尔类型可以被当作整数来对待
9.min-max标准化方法是对原始数据进行线性变换
四、简答题(4*2)
大数据发展历程:出现阶段、热门阶段和应用阶段 P2
大数据影响 P3
1)大数据对科学活动的影响
2)大数据对思维方式的影响
3)大数据对社会发展的影响
4)大数据对就业市场的影响
大数据对思维方式的影响:
1.人们处理的数据从样本数据变成全部数据
2.人们不得不接受数据的混杂性,放弃对精确性的追求
3.人类通过对大数据的处理放弃对因果关系的渴求,转而关注相关关系
大数据特征:数据量大、数据类型繁多、数据产生速度快及数据价值密度低 P5
大数据与云计算的联系:
大数据与云计算都较好地代表了IT界发展的趋势,二者相互联系,密不可分。云计算就是计算机硬件资源的虚拟化,而大数据是对海量数据的高效处理。
区别:
1.在概念上两者有所不同,云计算改变了IT,而大数据改变了业务。然而大数据必须有云作为基础架构才能得以顺畅运营
2.大数据和云计算的目标受众不同,云计算是CIO等关心的技术层,是一个进阶的IT解决方案。而大数据是CEO关注的,是业务层的产品,大数据的决策者是业务层。
综上,大数据与云计算二者已经彼此渗透,密不可分。
大数据与人工智能的区别:
1.在概念上两者有所不同,大数据和云计算可以理解为技术上的概念,人工智能是应用层面的概念,人工智能的技术前提是云计算和大数据
2.在实现上,大数据主要是依靠海量数据来帮助人们对问题做出更好判断和分析,而人工智能是一种计算形式,它允许机器执行认知功能。
综上所述,虽然它们有很大区别,但人工智能和大数据仍然能够很好地协同工作。二者相互促进,相互发展。
数据清洗流程:
1.预处理
2.缺失值清洗
3.格式与内容清洗
4.逻辑错误清洗
5.多余的数据清洗
6.关联性验证
数据标准化是通过一定的数学变换方式将原始数据按照一定的比例进行转换,使之落入一个小的特定区间内
数据抽取流程:
1.获取数据
2.整理、检查和清洗数据
3.将清洗好的数据集成,并建立抽取模型
4.开展数据抽取与数据转换工作
5.将转换后的结果进行临时存放
6.确认数据,并将数据最终应用于数据挖掘中
Spider开发流程:
1.继承scrapy.Spider
2.为Spider命名
3.设置爬虫的起始爬取点
4.实现页面的解析
五、名词解释(3*2)
1.大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合。
2.1秒定律:要在秒级时间范围内给出分析结果,若超出这个时间,数据就失去价值了
3.大数据采集技术就是对数据进行ETL操作,通过对数据进行提取、转换、加载,最终挖掘数据的潜在价值,然后给用户提供解决方案或决策参考
4.网络爬虫又称网络机器人、网络蜘蛛,是一种通过既定规则能够自动提取网页信息的程序
5.数据可视化是关于数据视觉表现形式的科学技术研究
6.大数据存储是将数量巨大且难以收集、处理、分析的数据集持久化到计算机中
7.数据清洗的含义是检测和去除数据集中的噪声数据和无关数据,处理遗漏数据,去除空白数据域和知识背景下的白噪声
8.数据抽取是指从数据源中抽取对企业有用的或感兴趣的数据的过程
9.网页数据提取
10.数据采集又称数据获取,是指利用某些装置从系统外部采集数据并输入系统内部的一个接口
11.数据标准化是通过一定的数学变换方式将原始数据按照一定的比例进行转换,使之落入一个小的特定区间内
六、阅读程序(10*1)
还要看P52代码

 七、操作题(10*4)
七、操作题(10*4)